HiTTOを支える技術について(インフラ編)
HiTTO株式会社エンジニアのHonMarkHuntです!HiTTOではSREとスクラムマスターとFORTNITEをして過ごしています!趣味はGOLD'S GYMです!よろしくお願いします!
本日はSREの私がバックエンド、フロントエンドに続きHiTTOのインフラ周りの紹介をさせていただきます!
(過去記事も見てね)
1. Cloud

HiTTOではAWSを採用しています。
GCPやAzureと比較して明確な採用基準があったわけではなく、私含め皆AWSが慣れていたので採用しました。
Organizationを利用して環境ごとにアカウントを分けたマルチアカウント運用をしています。
アプリケーションの構成に関しては特別なことはあまりなく平均的なWebアプリケーションの構成という感じです。 主に使用しているサービスを以下に記載させていただきますが、なんとなく平均的な感じが見えてくると思います。
- ALB
- ECS(fargate)
- RDS
- CloudFront
- S3
少しだけ頑張った点をお話しするとログインは全てGSuiteのsaml認証に統一しており、入社時にGSuiteアカウントを発行すればAWS側でIAM Roleを作成したりUserを作成したりといった手間が発生せず、退職した場合もGSuiteアカウントが削除されるのでAWS側でのアカウント管理が必要なく若干のトイル撲滅になっております。
aws.amazon.com (同じような事してる記事が古いのしか見つからなかった)
2. IaS

AWSの構成管理にはTerraformを採用しております。
HiTTOはまだまだスタートアップのフェーズでこの人数規模で構成管理を導入するかは少し迷ったのですが
- コンソールから操作していて悪意のない破壊的変更があった場合元に戻すことができる
- コードによる構成管理をする事で適用前にレビューができる
- 再利用性が高まり複数アカウント間で同じようなリソースを作成する際の手間とミスが減る
以上のメリットが考えられたため導入を決定しました。Terraformを採用したのは Cloud Formationが辛すぎるからだよ^^ 前職で利用経験があり開発も活発だったためです。
Terraformの構成については1年ほど前ですがこちらの超人気記事を執筆してあるので詳しくはこちらをご覧になってみて下さい。
開発フローに関しても手元でコードを書いてからコードがインフラに反映されるまでをCI/CDを導入して自動化しており、こちらに関しても今年のHashi Talksで超人気セッションと一部で囁かれた雰囲気のする登壇をさせていただいているのでこちらをご覧になってください。
www.slideshare.net (動画もあるけど恥ずかしいから貼りません君の目で確かめてくれ!)
3. CI/CD

CI/CDはCircleCIを採用しています
こちらは前職でAWSのCode Pipelineを使用していましたがそれによってかなり疲弊してしまい、CircleCIを使っておきたい人生だったなぁ...と感じたため採用しました。Code PipelineとCircleCIを比較した内容で登壇させていただいたことがありこちらも大人気資料になっているのでもし良かったらご覧になってみてください。
www.slideshare.net
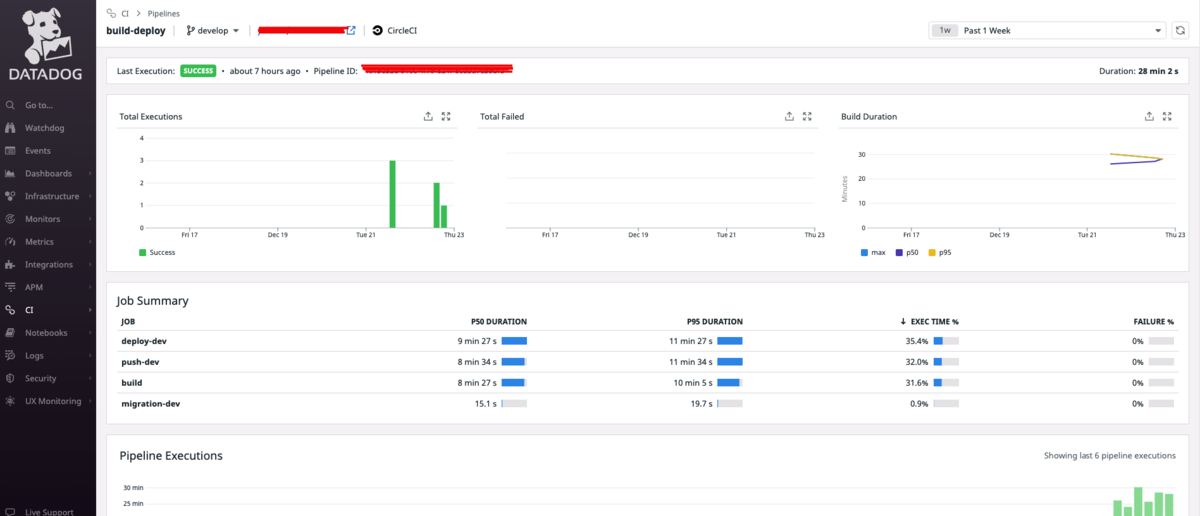
個人的な考えですが、CI/CDの仕組みは一度作ってはい終わりではなくアプリケーションやチームの変化に応じて変更・改善し続けるものだと捉えています。そしてカイゼンするためには現状を把握することが何より必要です。
皆さんも「ビルド遅くなってきたからなんとかしたいな〜」や「最近CIこけるけど再実行したら通るから一旦いっか...」のようなやりとりをなどSlackで見たことはないでしょうか? ここで重要なのはなんとなくの体感値で動き出すのではなく
- ビルドのどのjobに平均時間がかかっているか
- 失敗率は何%なのか
- ビルド時間が増加傾向にあるか
などなどを明確に可視化することで、目標値を決めてカイゼンの一手が打てるようになります。
前置きが長くなりましたが、HiTTOではData Dogを使用してCIのメトリックスを集計・可視化しています。 まだできていませんが、将来的には目標値を決め下回った場合にはSlackにalertを出してカイゼンを行うなど、CIを利用するエンジニアに向けてのSLI/SLOを定義して運用していくことをやっていきたいと考えています。
4. Monitoring

データの収集・可視化・アラーティング等、多岐にわたってData Dogを利用しています。
Data Dog以前は、サーバーの監視にZabbix、Logの閲覧にElastiCache + Kibana、アラーティングにPager Duty、などそれぞれでツールを用意する必要がありましたが、Data Dog登場以降は「とりあえずDD入れておけばあとはなんとかなる」のとかなり有能な機能アップデートが頻繁にある点が素晴らしいと感じ弊社でも採用しています。
弊社で主に使っているサービスは
Logs
アプリケーションのログからLB、S3などなどありとあらゆるログの収集とアラーティングに利用しています。 ログはすべてjson形式で送っておりjsonで送ればData Dog側でかなり良しなに解釈してくれるのでとても助かっています。
APM
バックエンドのプロセスをAPMでメソッド単位の処理時間まで確認できボトルネックを特定することができ見るたびに「APMすげえな」と言っています。
RUM
フロントエンドでの実ユーザーの情報を収集し可視化しています。 今のところ集めるだけになってしまっていますが、ソースマップを使ってエラーのアラーティング、APMとの連携などを進めていきたいです。
(Data Dogにある情報センシティブすぎてスクショが乗せれずすみません)
まとめ
今の環境は0⇨1で物作りする楽しさが詰まっていて、詰まりに詰まって(タスクが)溢れかえっています。 2人目のSREに入社して欲しいです。 今気づいたんですけど弊社の求人、SREだけ出ていないので僅かでも興味を持っていただいた方はとりあえず僕にDMください。マジで頼む。
Best regards.